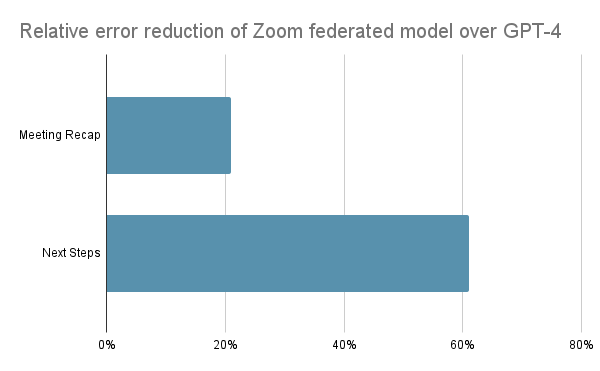
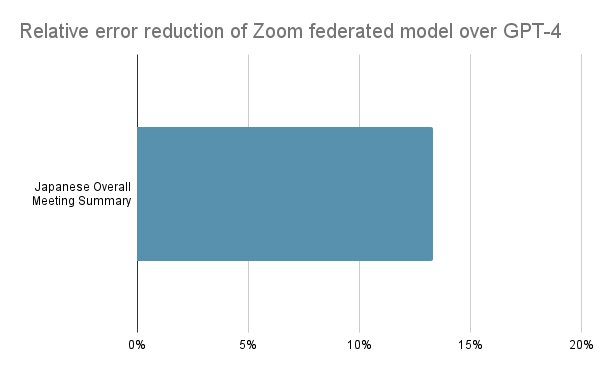
In November 2023, I shared how Zoom’s federated AI approach achieved quality nearly equal to OpenAI GPT-4 with only 6% of the inference cost. As impressive as those results were, we can now deliver even better AI quality compared to OpenAI’s GPT-4 for our most popular meeting features. Zoom AI Companion reduced relative errors by over 20% (for Zoom meeting summary’s “recaps”) and 60% (for “next steps”) in comparison to GPT-4 in our internal human-validated blind benchmarking.
In support of our training efforts to refine task completion quality, our unique federated approach to AI takes advantage of many closed- and open-source advanced large language models (LLMs) working together for better results. This is in contrast to other providers who are tied to specific LLMs. For example, Microsoft Copilot has relied on GPT-4 and Google has relied on Gemini.
This approach to AI sets Zoom AI Companion apart, providing our customers with a high-quality experience with our most popular features. As I shared in my last update, we use our proprietary Z-scorer to judge the quality of our AI-generated outputs. First, we employ a lower-cost LLM most suitable for each task. Then, our Z-scorer evaluates the quality of the initial task completion. If needed, we can use another complementary LLM to refine the task. This process results in a higher-quality output in the same way a team of people can accomplish more together than any one individual.
We’ve since improved our Z-scorer by incorporating additional quality signals from a variety of LLMs. Also, to better align with human preference, we improved federated reinforcement learning. By federating Zoom LLM in combination with a set of complementary LLMs, Zoom’s popular meeting summary delivers high-quality results and, according to our recent benchmarking, can now outperform GPT-4, which is used to power Copilot in Microsoft Teams.
Regarding AI safety, we also reduced the inherent bias in most LLMs by forming a committee composed of multiple LLMs such as Claude-3, Gemini, and GPT-4 to reduce hallucinations and improve our Zoom LLM. For example, different LLMs are unlikely to make the same hallucinated mistake, so we can derive more consistent responses and reduce the impact of outliers.